🎁 [Độc Quyền] Tặng Mã Khuyến Mãi 1 Năm MiConvert Plus (Trị Giá 50$) Cho Sinh Viên FPT Polytechnic
Chào các chú "Ong Vàng" FPT Polytechnic! Với phương châm "Thực học - Thực nghiệp", khối lượng bài tập, dự án (Assignment...
Chào các chú "Ong Vàng" FPT Polytechnic! Với phương châm "Thực học - Thực nghiệp", khối lượng bài tập, dự án (Assignment...
Trong quá trình học tập và giảng dạy, việc làm việc với các tệp PDF là điều không thể tránh khỏi. Từ bài giảng, tài liệu...
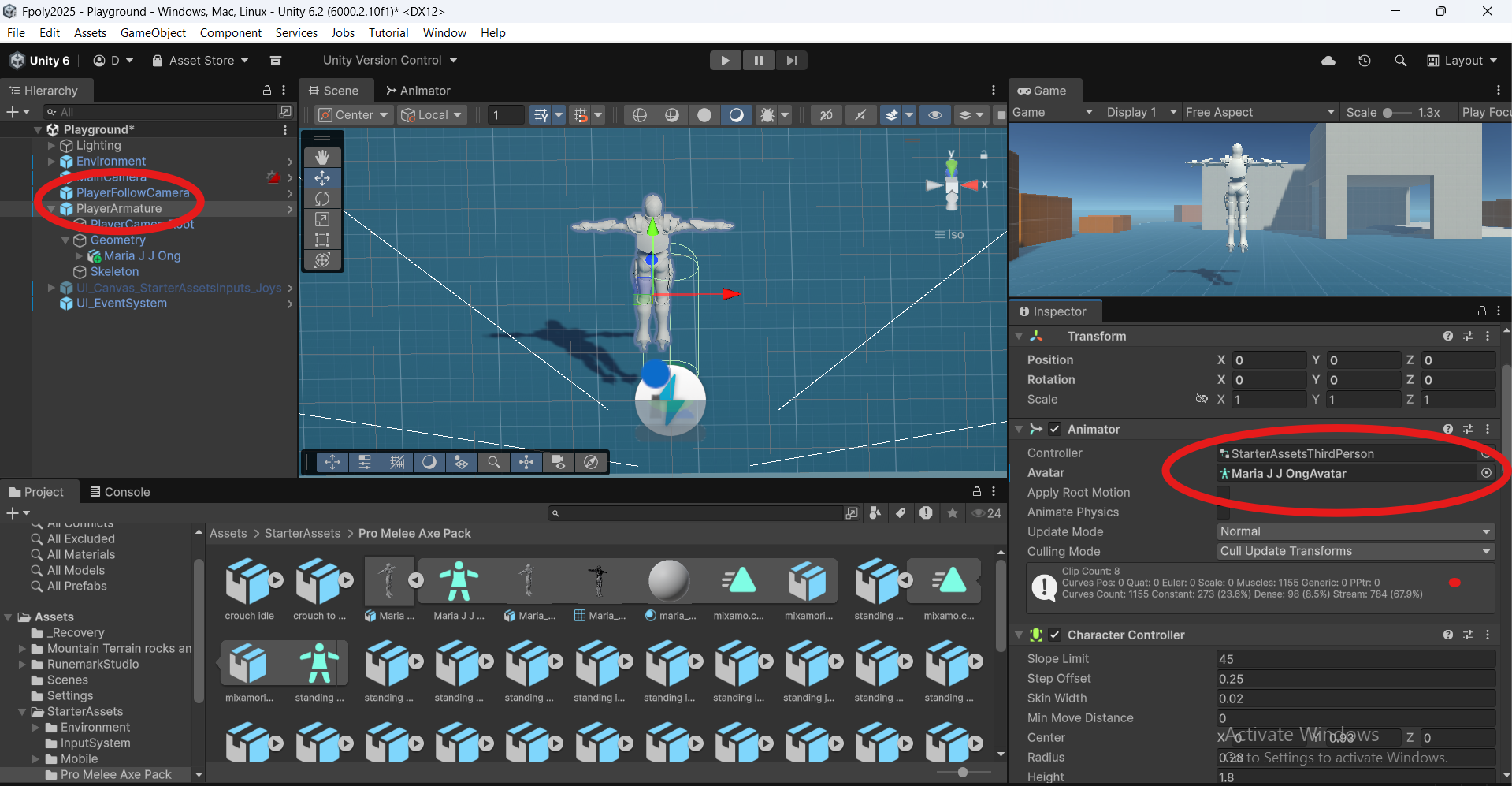
Tiếp tục bài trước , ở bài này , chúng ta sẽ tiến hành thêm các hành động khác của nhân vật và tiến hành bắt sự kiện khi...
Hi các em, trong bài viết này thầy hướng dẫn cách tùy chỉnh, bổ sung Animation, sự kiện cho gọi starter assets third per...
Năm 2026 đang đến gần và ngành công nghiệp phần mềm tiếp tục phát triển với tốc độ chóng mặt. Dưới đây là những xu hướng...
Hi các em, bài viết này thầy hướng dẫn và giải thích các loại nguồn sáng trong Unity 3D Nguồn sáng ( Lighting ) rất thư...
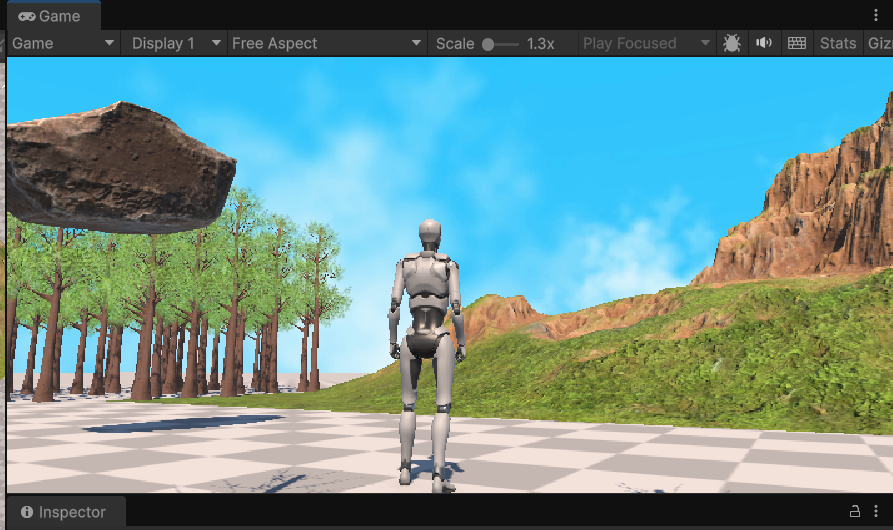
hi các em, trong bài viết này thầy hướng dẫn chi tiết cách tạo Material Sky Box trong Unity Game 3D ( làm bầu trời trong...
Chào các em! Trong những năm gần đây, trí tuệ nhân tạo (AI) đã thay đổi hoàn toàn cách chúng ta lập trình. Từ việc phải ...
Hi các em, trong bài viết này thầy sẽ hướng dẫn thật chi tiết và dễ hiểu cách thêm ảnh (texture) vào một mô hình 3D tron...
Cài Đặt Composer Composer là công cụ quản lý dependencies không thể thiếu khi làm việc với Laravel. Dưới đây là cách cài...
1. Giới thiệu nhanh Gần đây, OpenAI đã ra mắt trình duyệt ChatGPT Atlas – một trình duyệt được thiết kế đặc biệt tích hợ...
Bài hướng dẫn tạo dự án Restful API điểm xếp hạng cho Game Unity bằng .Net Framework Bước 1 : Mở SqlServer trên máy tính...